Actualité - 27 janvier 2022
#FocusProjet ISSA, l’intelligence artificielle au service de la recherche bibliographique
Le projet ISSA – Indexation Sémantique d'une archive scientifique et Services Associés pour la science ouverte – est lauréat de l’appel à projet CollEx-Persée 2020.
Ces dernières années, plusieurs phénomènes ont complètement modifié la manière dont les chercheurs interagissent avec la littérature scientifique. Les volumes de publications explosent, que ce soit dans des revues et conférences avec actes, ou au travers de dépôts en prépublication (par exemple arxiv.org), de sorte qu’il peut être difficile de s’y retrouver et d’identifier les articles pertinents ou même des collaborateurs potentiels. Le projet Issa s’appuie sur l’indexation sémantique des publications d’une archive ouverte pour offrir aux chercheurs des outils leur permettant d’explorer plus facilement cette masse de connaissances.
Dans ce billet, nous présentons les différentes étapes suivies dans ce projet pour relever ce défi. Deux objectifs principaux sont visés :
- traiter le contenu d’une archive scientifique ouverte afin de produire un index sémantique représenté sous la forme d’un graphe de connaissances ;
- développer des services innovants de recherche et de visualisation capables d’exploiter cet index sémantique.
Ce projet s’adosse à un cas d’usage spécifique, l’archive ouverte des publications du Cirad, Agritrop, sur laquelle tous les développements sont mis en œuvre.
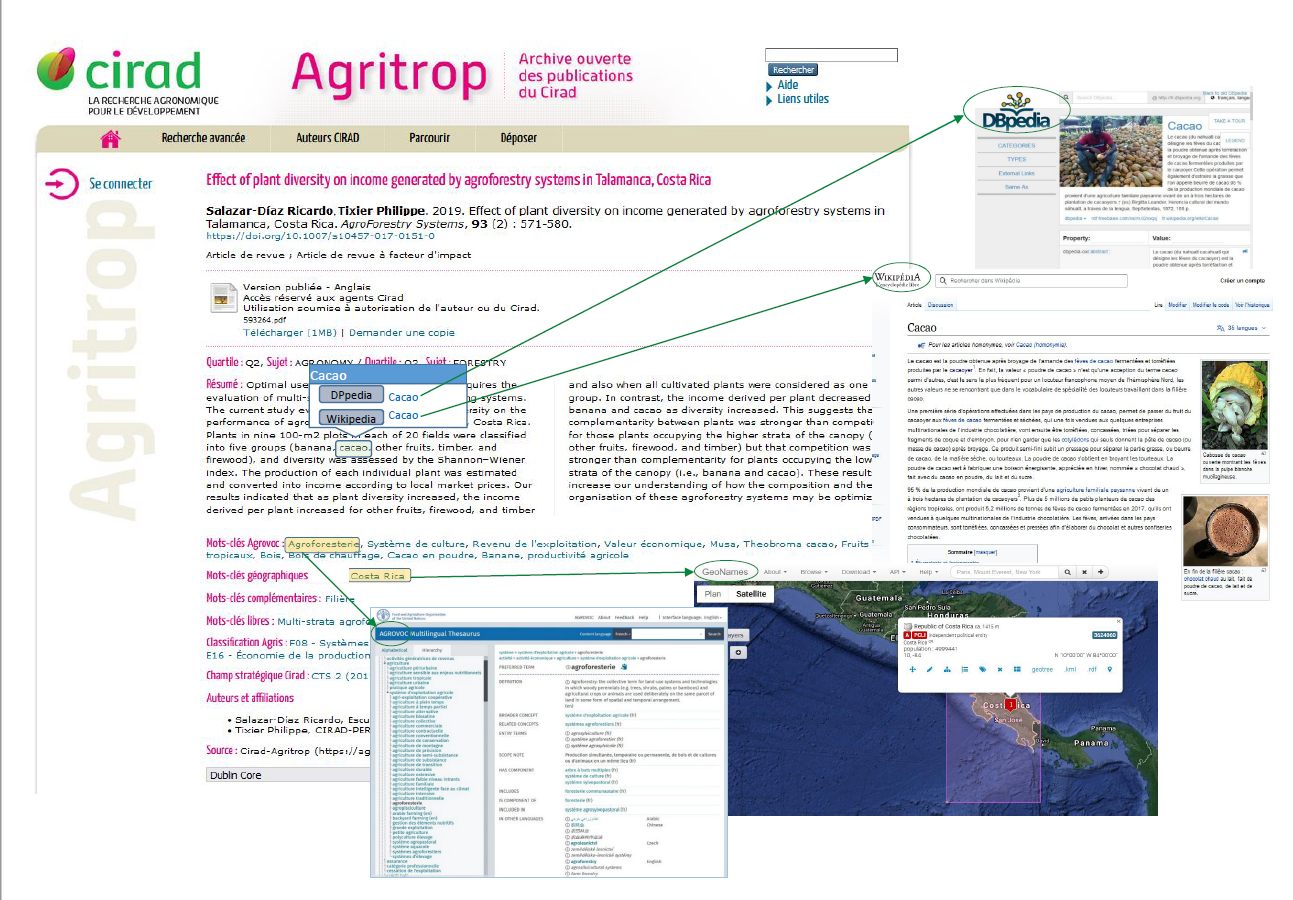
Le premier volet du projet (objectif 1) est en cours de finalisation. Le processus de construction de l’index sémantique fait appel à diverses techniques d’intelligence artificielle : traitement du langage naturel, ingénierie des connaissances, web sémantique et données liées. Ces techniques permettent de traiter les métadonnées des publications ainsi que le texte intégral des articles (pour ceux disponibles en libre accès) afin d’en extraire automatiquement des descripteurs thématiques et des entités nommées. La base de connaissances ainsi créée établit des liens avec des référentiels standard (ontologies, thésaurus, etc.) tels que Wikidata, DBpedia, Agrovoc, GeoNames. Les données produites sont stockées dans une base de données RDF (triple store) qui sert de clé de voûte au développement de services de recherche ou de visualisation.
Le second volet (objectif 2) a pour focus le développement de services. Un préalable a consisté à mener une enquête auprès de chercheurs du Cirad, de manière à déterminer plus précisément leurs besoins et proposer des services de recherche bibliographique adaptés. L’analyse de ces entretiens a permis d’orienter nos choix vers les premières réalisations de services et les pistes à explorer. Un premier service permet déjà de visualiser les notices d’articles enrichies par l’indexation automatique (mots-clés thématiques et géographiques) ainsi que l’affichage (optionnel) des entités nommées dans le résumé avec un lien vers des ressources externes (exploration du Web des données) et la visualisation des entités nommées géographiques sur une carte.
Voir la page projet ISSA > ici
Anne Toulet,
Ingénieure de recherche, chargée de projet Web Sémantique et Web de données – Dist, Cirad
Franck Michel,
Ingénieur de recherche en informatique – Laboratoire I3S, Université Côte d’Azur, CNRS, InriaAndon Tchechmedjiev
Maître de Conférences en informatique – EuroMov Digital Health in Motion, Univ. Montpellier, IMT Mines Alès#ProjetCollExPersée
Une actualité ou un événement à partager avec nous ?
Proposez vos actualités et événements afin qu'ils soient publiés sur le site du CollEx-Persée
